
Seamless flow of Data in Different Layers of Cloud
Challenges
A major hospitality company struggled with scaling its subsidiary business in the US because of the on-premise data storage infrastructure. The storage systems were complex and expensive to design and set up, altering the workflow and hindering the business objectives. Consequently, affecting revenue generation.
Factspan utilizes Amazon Web Services for cloud migration and storage. The cloud providers allow the feasibility to rent its servers till the time the business needs them. Thereupon, reducing the cost to almost half. However, the migration process is not easy because business users are accustomed to working in an on-premise environment.
Moreover, our team worked on creating multiple data pipelines, so that one server can be used for multiple projects. The team also worked on modernizing the database by migrating all the connection points to Snowflake, which is used as a data warehousing tool. One of the advantages after data modernization is now the real-time data is visible over the dashboards.
Solutions
Factspan helped the organization to build a data ingestion solution. Our team utilized SPARK as a streaming engine to process the data and to promote it to different layers in S3 and Snowflake. In fact, the team developed and implemented the solution using tools like Python, Pyspark, Snowflake, AWS, UC4 (for scheduling).
The client partnered with us to seamlessly process and promote their data in different layers of the cloud. Our solution helped the company interact with real-time data by updating every new data point in an automated manner and adjusting their business decisions by studying everyday data and changing market conditions. It supported their teams to reimagine faster work processes, effectively track performance across all segments and geographies and better identify the cash flow problems.
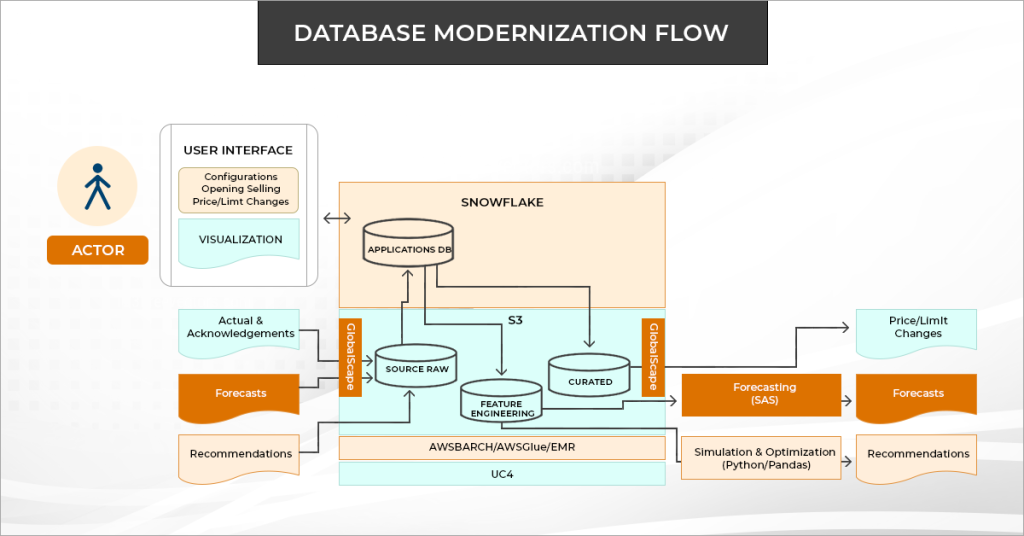
Factspan led the team to develop and implement ingestion data pipelines in AWS Cloud using AWS Batch & Snowflake.
- The team created a dynamic data and batch validation framework for Snowflake tables.
- To orchestrate the data downstream, our team parsed Extensible Markup Language (XML) files, Yet Another Markup Language (YAML), Javascript Object Notation (JSON), and various unstructured data from real-time API using our own framework.
- Incorporated optimization solver – Gurobi to the AWS batch and replaced the traditional servers to cloud mechanism for the faster real-time simulation
Results / Impact
- Improved the processes of the revenue opportunity of $16.5 Billion
- Reduction of on-premise storage infrastructure operational costs while increasing the effectiveness of processes
- Fast track and automatic upgrades on the essential processes
- Smooth business scalability when the application experiences huge traffic
Why Factspan?
Experience Unparalleled Data Modernization with Factspan
Featured content

Enterprise-Grade Automation for Data Pip...

Accelerating Cloud Migration with Automa...

Simplifying Complex Queries with Text-to...

Rivery Custom Connectors for Smarter Dat...

Modernizing Supply Chain & Vendor Ma...

Decoding Enterprise SQL Querying with G...

The Future of Data Pipelines for Modern ...

Streamlining Product Data for an Automot...

Optimizing Customer Data Management for ...
