Why this blog?
If keeping up with the rapid evolution of data pipelines feels challenging, this blog is for you. It breaks down the latest advancements, real-time processing, cloud-native architectures, AI integration, and automation, helping you understand how modern enterprises are optimizing data flow for speed, scalability, and efficiency. Whether you’re a data engineer, analyst, or decision-maker, this blog will provide key insights into building future-ready data pipelines that drive smarter business outcomes.
In today’s day and age, as data continues to have an ever increasing influence on decision-making, innovation and day-to-day operations, companies are depending on sophisticated data pipelines to obtain, process, and analyze vast amounts of data. However, with technological advancements, the data landscape is becoming more and more complex causing data pipelines to undergo significant transformation.
The need for ever-increasing speed and accuracy of processing is driving the need to build major innovations into the Data Landscape. Let’s get into the details of some of the noteworthy features that will define the Data Pipelines of the future
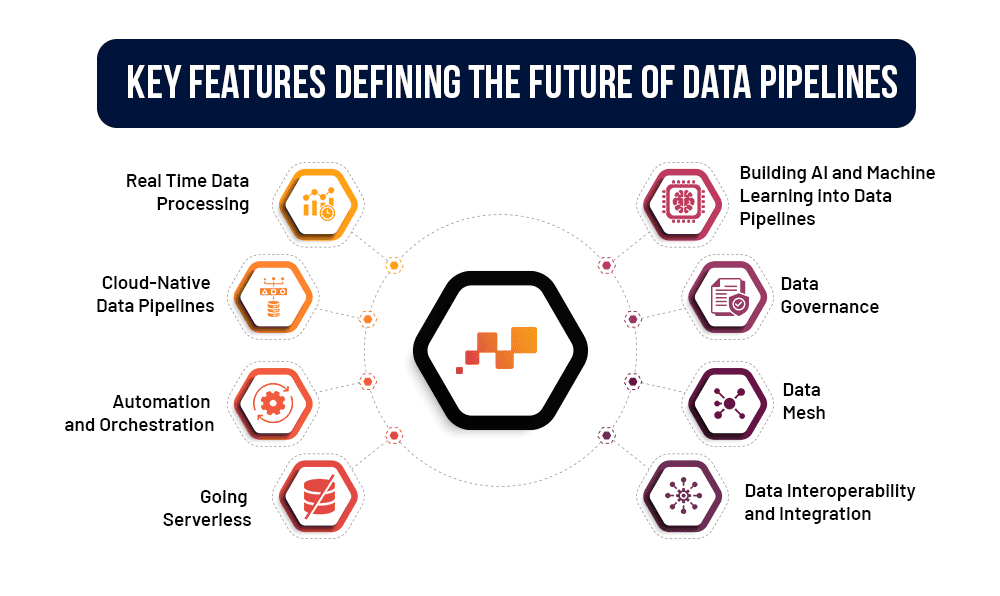
Real Time Data Processing
With an “A day old is ancient” approach, organizations are shifting their focus to Real Time Streaming with Data Pipelines following suite. Ingestion, processing and analysis of streaming data is enabling organizations to accelerate decision-making and responsiveness and also making sure that critical applications run on real-time or near real-time data. Technology offerings like Apache Kafka, Apache Flink and cloud based solutions like Google Cloud Data Flow, AWS Kinesis and Azure Stream Analytics are proving to be the enablers for this change.
Obvious benefits of this approach are:
- Real Time Insights into critical organizational aspects
- Improved Client Experience
- Enhanced Competitiveness
Cloud-Native Data Pipelines
Cloud-Native Data Pipelines have a huge advantage over traditional Data pipelines in terms of scalability, flexibility and cost-effectiveness. They can completely alter how organizations manage and utilize their data pipelines. Modern cloud-based data platforms like Snowflake, Databricks, and Google BigQuery can enable organizations to do-away with on-premise infrastructure and effectively leverage serverless computing, elastic scaling and use of managed services. Cloud Native Pipelines support a plethora of UpStream and DownStream systems which makes them more agile and adaptive as compared to traditional Data Pipelines. These factors also reduce the complexity of cloud native data platforms and thus, maintenance becomes more cost effective.
Automation and Orchestration
With the Data Landscape becoming increasingly complex, it is becoming very difficult for organizations to manage and monitor Data pipelines manually. Hence, organizations are moving away from this cumbersome approach to a more automated one. Automation of Data Pipelines ensures minimum human intervention in ingesting, transforming and analysing data. Orchestration tools manage the flow of tasks and ensure correct sequence. Both of these reduce human error, increase the velocity and scalability of data delivery and improve efficiency of resources, both human and machine.
Orchestration platforms like Kubeflow, Apache Airflow, Apache Nifi, Prefect, AWS Step Functions and Dagster, to name a few, help enterprises design and manage increasingly complex Data Pipelines and provide better visibility of the overall data landscape.
Going Serverless
Serverless Frameworks allow organizations to create Data Pipelines which have the ability to scale automatically based on demand. This makes them capable of handling data spikes and low usage without human intervention. This helps organizations optimize their cost over a period of time.
Offerings like AWS Lambda, Azure Functions, and Google Cloud Functions enable Serverless Computing for organizations and in turn, make them better equipped to handle any kind of data load.
Building AI and Machine Learning into Data Pipelines
Integration of AI/ML capabilities has opened up a whole new world for Data pipelines. Use cases can range from anomaly detection, automated data cleansing and transformation to providing predictive insights without human intervention.
AI/ML can enable organizations to make their decision-making process more robust by automatically detecting data quality issues. It can enable organizations to reduce the turn-around times for issues related to their critical systems like supply-chain, manufacturing, sales forecasting, workforce management and marketing analytics just to name a few.
Data Governance
Data Privacy guidelines and regulations like GDPR, HIPAA and CCPA require organizations to ensure that sensitive data is encrypted, access-controlled and traceable at all times. Data Pipelines of the future will follow a “Privacy Embedded in Design” approach rather than considering Data privacy as an Add-On implementation. This approach will make sure that Efficiency, security and ethics go hand in hand while helping organizations enforce governance frameworks, ensure compliance to global standards and reduce the risk of breaches.
Data Mesh
With the exponential growth in data volumes and the increase in organizational complexity, many large organizations are choosing to move towards a Data Mesh architecture. A Data Mesh decentralizes data ownership which means that different organizational units manage their own data. This approach enhances data quality as domain experts for each organizational unit have complete control of their own data pipeline. A certain level of hand holding among the organizational units in terms of standards and governance can also help avoid the usual issues which come in while working with siloed units. This is brought in by advanced orchestration and governance tools which bring in consistency and security across the organization.
Data Interoperability and Integration
Interoperability will be the defining factor in the future of data pipelines. The success or failure of a Data Pipeline will depend on, among other things, the ability to integrate different platforms, tools and environments. E.g. Organizations will need to enable seamless integration among on-premise, Cloud and SaaS data platforms.
Data Integration platforms like Rivery, Fivetran, Stitch and Talend enable organizations to seamlessly connect different data platforms and aggregate data from different sources into an organization’s data ecosystem. Each one has its strengths e.g. Rivery is known to offer a wide range of customizations in its offering.
The evolution of data pipelines is redefining how organizations utilize data for strategic advantage. Agility, intelligence, scalability along with interoperability and governance will be the characteristics that define a robust Data Pipeline of the future. They will help businesses unlock new opportunities and remain competitive through data based decisions. Organizations that can harness the potential of these Data Pipelines will be able to stay ahead of the competition and achieve sustained growth and success.
Is your data infrastructure keeping up with your business growth?
Let us help you build an efficient, future-ready foundation for your data needs!


Rivery Custom Connectors for Smarter Data Integrat...

Modernizing Supply Chain & Vendor Management f...

Streamlining Product Data for an Automotive Techno...

Optimizing Customer Data Management for a Regional...

Mastering Prompt Engineering Techniques – Pa...

Mastering Prompt Engineering Techniques – Pa...

Exploring Data Mesh – PoV...

Data Governance – Starter Kit...

