
Why this blog?
Get a comprehensive understanding of LLMs and why prompt engineering is crucial for making the most out of conversational AI. This blog explains how to overcome common challenges of basic prompts with actionable strategies for clarity, structure, and enhanced output quality. Perfect for developers, product teams, and anyone working with AI, this guide provides insights into transforming simple AI queries into impactful, tailored results.
Prompt Engineering for Conversational AI
The evolution of artificial intelligence has brought us to an era where machines can understand and generate human language with astonishing proficiency. At the heart of this revolution are Large Language Models (LLMs), which have transformed the landscape of conversational AI and opened up new horizons in how we interact with technology.
Basic LLM Concepts
What are LLMs?
Large Language Models (LLMs) are advanced AI systems trained on extensive datasets comprising text from books, articles, websites, and other digital content. These models are designed to understand, generate, and manipulate human language in a way that is coherent and contextually relevant. By learning patterns in language usage, grammar, and semantics, LLMs can perform tasks such as:
- Text Generation: Crafting human-like text based on prompts
- Translation: Converting text from one language to another
- Summarization: Condensing long documents into concise summaries
- Question Answering: Providing answers to questions based on learned information
- Conversational Agents: Engaging in dialogues that simulate human conversation
The significance of LLMs lies in their ability to process and generate language without explicit task-specific programming. This makes them incredibly versatile tools across various domains, from customer service chatbots to writing assistants and educational tools.
Types of LLMs
There are several types of LLMs, each with unique architectures and capabilities. Some of the most notable include:
- GPT (Generative Pre-trained Transformer): Developed by OpenAI, models like GPT-3 and GPT-4 are among the most advanced, capable of generating highly coherent and contextually appropriate text.
- BERT (Bidirectional Encoder Representations from Transformers): Created by Google, BERT is designed for understanding the context of words in search queries, improving search engine results.
- T5 (Text-to-Text Transfer Transformer): Also by Google, T5 treats every NLP problem as a text-to-text task, allowing for a unified approach to diverse language tasks.
- XLNet: An advanced autoregressive language model that outperforms BERT on several benchmarks by leveraging a permutation-based training approach.
Each model varies in terms of:
- Architecture: The underlying design, such as transformers, which are neural network models adept at handling sequential data.
- Size: Measured in parameters; larger models generally have more capacity to learn complex patterns but require more computational resources.
- Training Data: The corpus of text used during training influences the model’s knowledge base and language style.
How are LLMs Built?
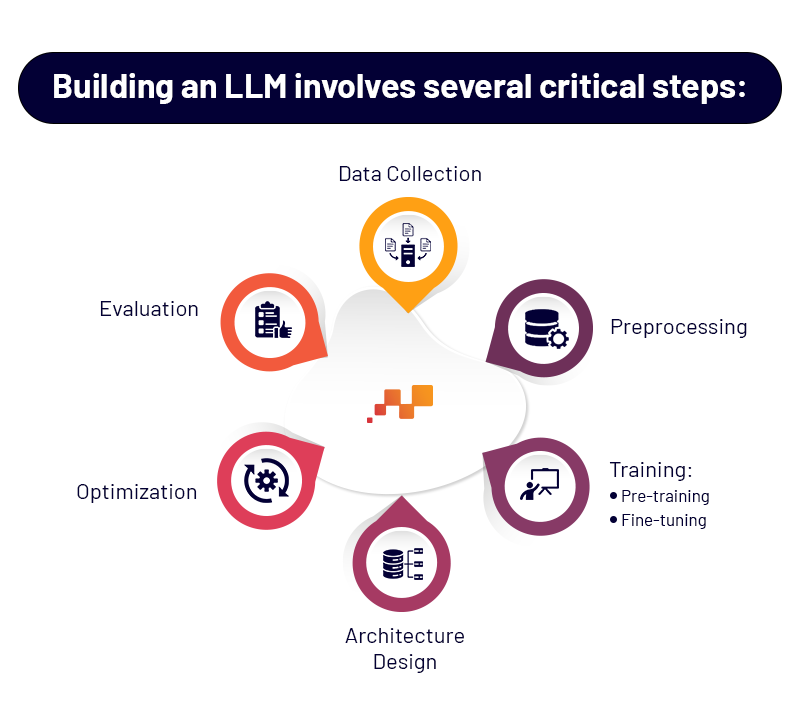
Developing a Large Language Model (LLM) requires several essential steps:
- Data Collection: Gathering vast amounts of text data from diverse sources to provide the model with a broad understanding of language usage.
- Preprocessing: Cleaning and organizing data to ensure quality. This includes tokenization (breaking text into units), normalization, and removing irrelevant content.
- Training:
- Pre-training: The model learns general language patterns through unsupervised learning, predicting the next word in a sentence or filling in blanks.
- Fine-tuning: Adjusting the model on specific tasks or domains using supervised learning with labeled datasets.
- Architecture Design: Utilizing neural network architectures like transformers that can handle long-range dependencies and contextual relationships in text.
- Optimization: Adjusting hyperparameters (learning rate, batch size) and employing techniques like regularization to improve performance and prevent overfitting.
- Evaluation: Testing the model on benchmark datasets to assess its capabilities and identify areas for improvement.
The process demands significant computational power and resources, often requiring specialized hardware like GPUs or TPUs.
Vocabulary
Understanding LLMs involves familiarizing oneself with key terms:
- Token: The smallest unit of text processed by the model (words, characters, or subwords).
- Parameters: The weights and biases within the neural network that are adjusted during training.
- Embedding: A numerical representation of words or tokens in a continuous vector space, capturing semantic meanings.
- Transformer: A neural network architecture that uses self-attention mechanisms to weigh the significance of different words in a sentence.
- Context Window: The amount of text (in tokens) the model can consider at once when generating responses.
Basic Prompting
The Art of Asking
At its core, interacting with an LLM is about crafting prompts—the questions or statements you present to the model to elicit a response. In basic prompting:
- Simple Questions Yield Simple Answers: Asking direct questions like “What is the capital of France?” will yield straightforward answers (“Paris”).
- Limitations of Basic Prompts: While useful, basic prompts may lead to:
- Ambiguity: Vague questions can result in unclear answers.
- Lack of Depth: Without additional context or instruction, responses may be superficial.
- Inconsistency: Similar prompts may yield varying responses due to randomness in the model.
For example, asking “Tell me about the benefits of exercise” may produce a generic list, but lacks personalization or structure that could be achieved with a more detailed prompt.
The Need for Prompt Engineering
Challenges with Basic Prompts
As users began interacting more extensively with LLMs, they encountered several challenges:
- Ambiguity and Misinterpretation: The model might misinterpret vague prompts, leading to irrelevant or incorrect responses.
- Unstructured Outputs: Without guidance, the responses may lack the desired format, making it harder to extract actionable information.
- Inconsistent Style and Tone: Responses may not match the required level of formality or stylistic preferences.
- Inability to Handle Complex Tasks: Simple prompts may not suffice for tasks that require multi-step reasoning or specific instructions.
Prompt engineering emerges as the solution to these challenges. It involves carefully designing prompts to guide the LLM’s output effectively.
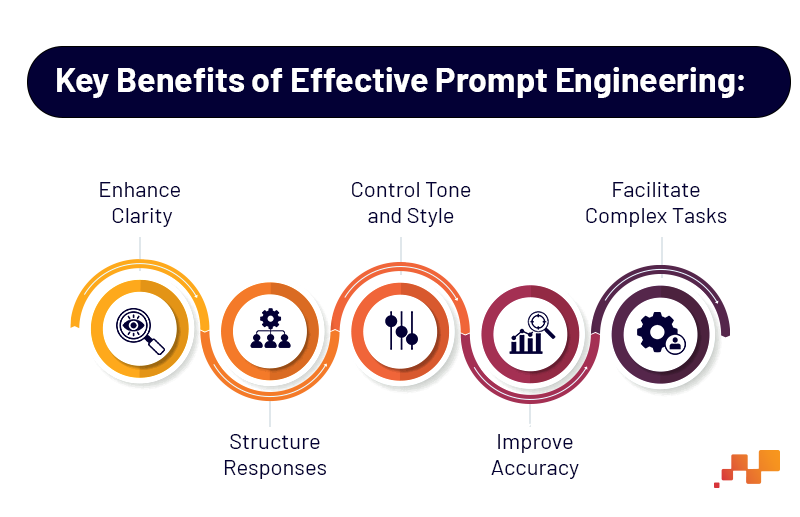
- Enhance Clarity: Providing specific instructions reduces ambiguity
- Structure Responses: Requesting answers in certain formats (e.g., bullet points, tables) makes information easier to digest
- Control Tone and Style: Specifying the desired tone ensures consistency with the intended audience or purpose
- Improve Accuracy: Including relevant context helps the model generate more precise answers
- Facilitate Complex Tasks: Breaking down instructions enables the model to handle multi-step processes
Real-life Scenario
Consider the difference between two prompts:
- Basic Prompt: “Write about renewable energy.”
- Response: A general overview that might touch on various aspects without depth.
- Engineered Prompt: “As a science journalist, write a 300-word article in a neutral tone about the latest advancements in solar photovoltaic technology, focusing on efficiency improvements and potential impacts on the energy market.”
- Response: A focused, well-structured article that meets specific requirements.
By engineering the prompt, the user obtains a response that is tailored to their needs, saving time and enhancing the usefulness of the output.
Understanding the basics of LLMs and the importance of prompt engineering sets the foundation for effectively leveraging these powerful tools. In the next part, we’ll delve deeper into how to craft good prompts, exploring techniques that transform simple interactions into productive collaborations with AI


The Future of Data Pipelines for Modern Enterprise...

Maximizing Sales ROI with Agentic AI...

Mastering Prompt Engineering Techniques – Pa...

Automating Patient Note Summarization Using Gen AI...

AI Co-Pilot for Smarter Contract Management...


Role of AI in BI – PoV...

Being Data Ready for Gen Al...

Gen AI-Infused Business Analytics for Enhanced Log...
