
Today, the digital world is growing in a complex form and is coiled in a storage volume, variety of structures and velocity. The democratization of PCs, laptops, smartphones and tablets, and the rising craze for social networks encouraged the exchange and production of new data. Besides the public data, a large piece of data is being released by organisations and companies too, known as Open-data. Businesses are looking into smarter decisions to process this massive dataset that provide agility, elasticity, centralized control and stability wherein, RDBMS, Relational Database Management System doesn’t have that efficiency to control cost, risk and security.

The addressed problem is based on the inefficiency of the relational database that failed in managing the growing demand for current data. The failure of the traditional form triggered many to move their content from RDBMS to Hadoop. But while migrating from RDBMS to Hadoop, the integrity of data is maintained and keeps the application code intact.
Why Hadoop?
Hadoop is not a database, it is a file system which is accustomed to processing and storing massive datasets across the computer cluster. Unlike RDBMS, Hadoop focuses on unstructured, semi-structured and structured data. Hadoop has two core components, HDFS and Map Reduce. HDFS is a storage layer and Map Reduce is a programming model which process the bulk of data sets by splitting into several blocks of data. These blocks are distributed throughout the nodes across the cluster. Hadoop can manage to store and process massive data where RDBMS fails to achieve higher throughput with large data. It can only manage when the volume of data is low. There are several factors Hadoop wins over RDBMS:
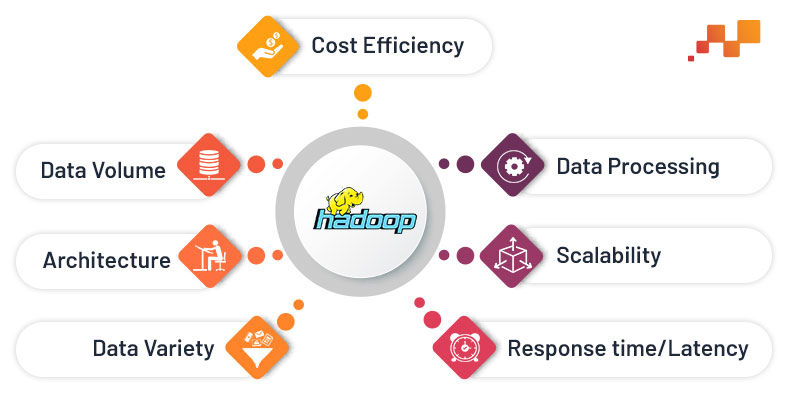
- Cost Efficiency
- Data Processing
- Scalability
- Response time/Latency
- Data Variety
- Architecture
- Data Volume
Cloud migration: RDBMS to Cloud

Approaches to Migrate Data from RDBMS to Hadoop
As mentioned above, data is expanding with increasing time and digital hub. This leads us desperately to the required sources for sophisticated analysis to meet businesses’ needs, address change in market dynamics as well as improve decision making. The bigger challenge is to capture this huge amount of data and then process it for better results. The traditional database is failing to maintain, store and process the big data. So, we came up with the approaches to Migrate RDBMS to Hadoop for better throughputs.
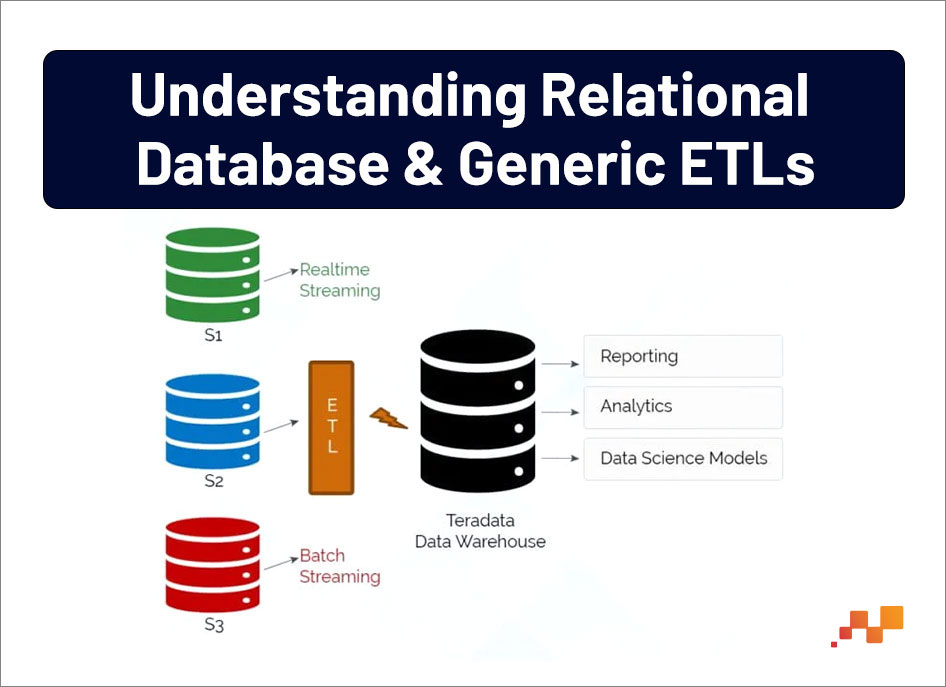
STEP 1: UNDERSTANDING RELATIONAL DATABASE AND GENERIC ETLS
For moving into step 1, it is important to understand the existing data layouts in RDBMS which includes Data Flow Diagrams, RDBMS Schema design, ETLs along with scheduling and connecting Applications. Collect the data and analyze the source to target mapping. Based on the requirements, the target can be a relational or flat file system.
STEP 2: RELATIONAL DATABASE AND ETL MIGRATION
For further offload of the relational data, move the data from system-generated tables & ETL, build equivalent schemas in Hadoop to load the Teradata sets and design workflows (ETLs) to move data from Teradata to Hadoop by using tools like Sqoop, Python & PySpark especially to migrate the ETLs. It needs to create a single Sqoop import command that imports data from a diverse data source into Hadoop. Then translate the Informatica ETLs to Hadoop equivalent using PySpark. And finally, run these ETLs in Hadoop environment to transform the data into the required structure and to record the Data Validation/Test cases.
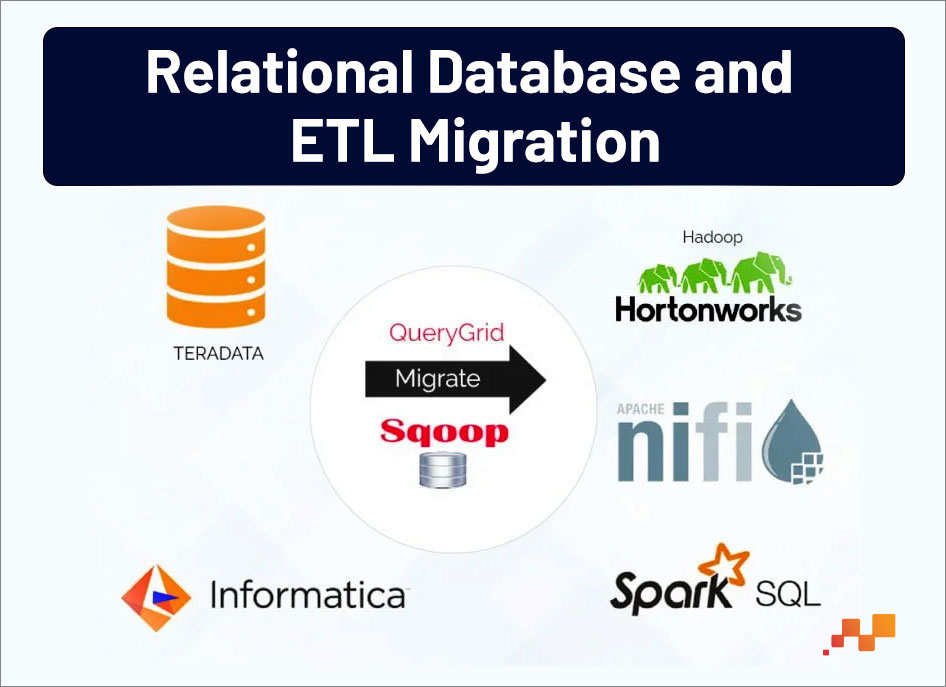
SQOOP
SQOOP is a command-line interface application that helps in transferring data from RDBMS to Hadoop. It is the JDBC-based (Java DataBase Connectivity) utility for integrating with traditional databases. SQOOP Import allows the movement of data into either HDFS (a delimited format can be defined as a part of the Import definition) or directly into a Hive table.
Python
It’s an object-oriented, high-level rare language that is designed with features to facilitate data analysis and visualisation. Python and big data are the perfect fit when there is a need for integration between data analysis and web apps or statistical code with the production database. With its advanced library supports, it helps to implement machine learning algorithms.
PySpark
PySpark is the Python API written in python to support Apache Spark. Apache Spark is a general-purpose, in-memory, distributed processing engine that allows you to process your data efficiently in a distributed fashion.
AWS Data Engineering Essentials Guidebook
STEP 3: INCREMENTAL MIGRATION: RELATIONAL DATABASE AND INFORMATIC ETLS
After historical migration, prioritize the sources need to relate to Hadoop and find the suitable tools/connectors like Spark, Sqoop to set up big data import pipelines from a source directly. Then design ETLs to parse and transform the data into required formats.
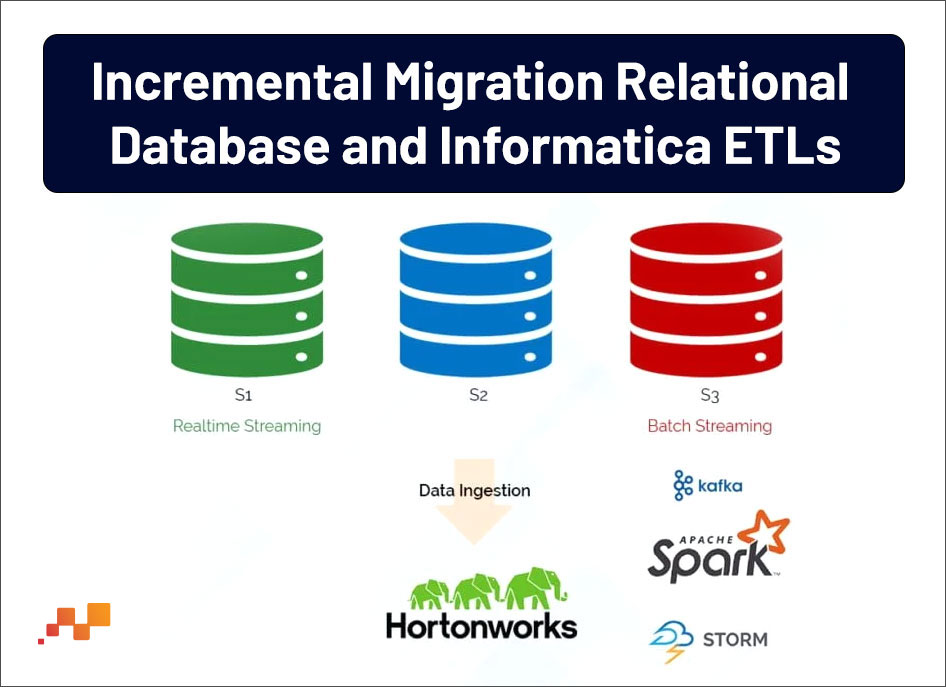
Now, we have to load the data into Hadoop and validate it to move from a source database to target data warehouse so that it can be joined with other data for analysis. It ensures that analysis can be performed for accurate results. Then we have to validate the Hadoop numbers with the relational database parallelly.
STEP 4: APPLICATION MIGRATION AND TESTING
Post Historical and Incremental Migration, we need to create a copy of the existing application(s) data from the relational database to Hadoop and perform regression testing. Regression testing helps assure whether new code changes shouldn’t have side effects on the existing functionalities. Moving forward, we process User Acceptance Testing (UAT) for the user scenario that has been done just before System Integration Testing (SIT). After performing further testing, we have to validate the business test cases. After this last process, the relational data is completely offloaded to the Hadoop system.

Hive – Apache Hive is a data warehouse software project built on top of Apache Hadoop for providing data query and analysis. Hive gives a SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
Where do we go next?
There is no going back to lower the data volume and to follow the traditional methods. Data will increase and it is important to get ready and deal with the upcoming challenges. The technology like Hadoop makes analysis possibly easy and RDBMS has its benefits. But when it comes to massive datasets, RDBMS fails and somehow it affects businesses’ major decisions. This is a reason for many to choose Hadoop over RDBMS.
Want to know more? Talk to our experts

Data Contract Implementation in a Kafka Project: E...


FAQs on Data Engineering Services...

How to Manage the Kafka Cluster...

Offset: Management and Role...

Optimizing Kafka: Architecture Insights and Perfor...
